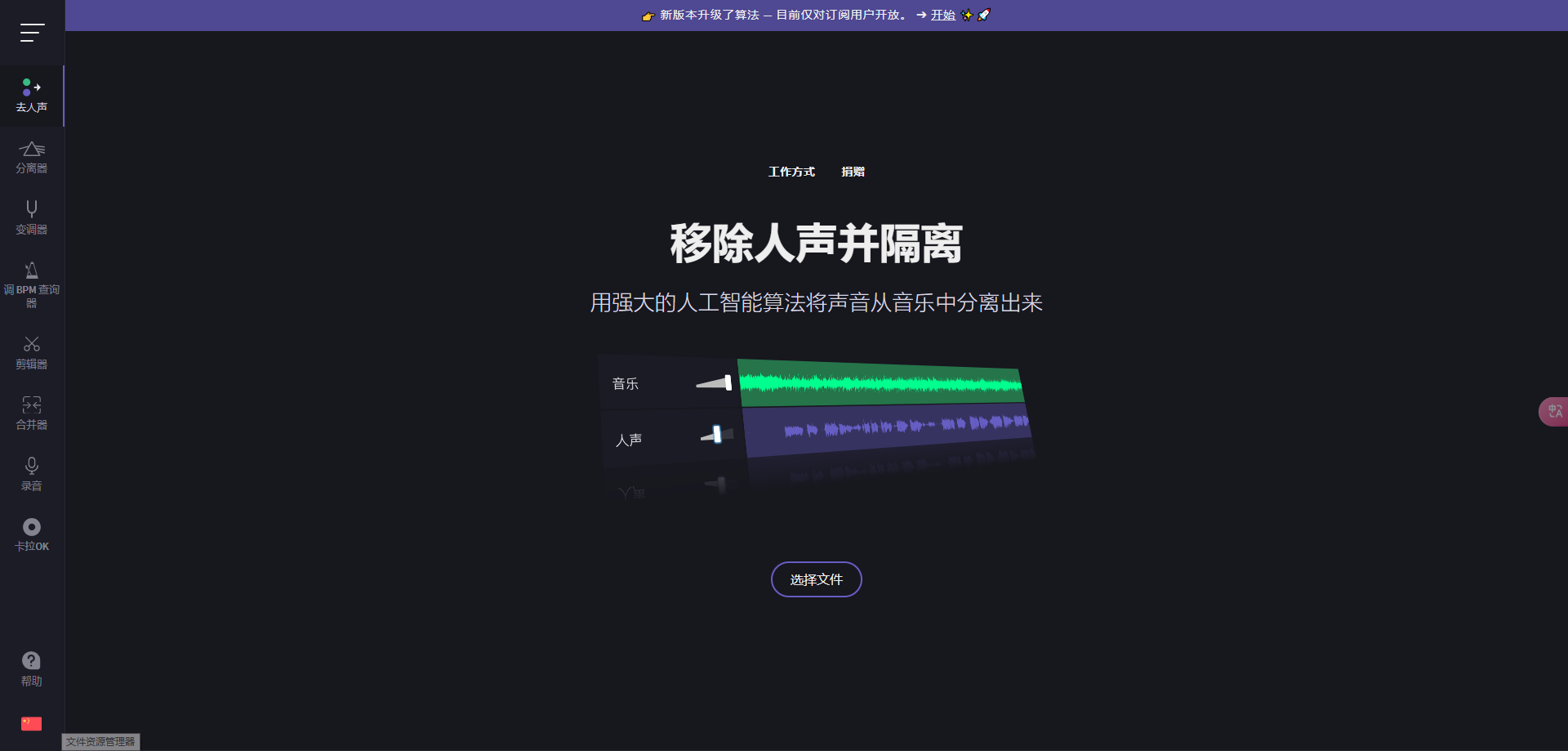
移除人声并隔离 用强大的人工智能算法将声音从音乐中分离出来

工作方式
这项技术通常依赖强大的人工智能算法,尤其是深度学习模型,通过分析音频信号中的频谱和时间特征来实现声音分离。其工作原理大概如下:
-
声音信号分离:
-
人工智能系统通过学习大量的音频数据,理解不同音轨(如人声、乐器、背景噪音等)的频谱和特征。
-
在分离人声和背景音乐时,AI模型会对每个音频片段进行分析,将声音信号按照其特性(如频率、音高、响度等)进行分离。
-
-
去除人声:
-
利用音频信号中的“人声特征”进行检测,AI算法可以有效地从整体音频中去除这些特定频率范围的声音。
-
通常这种处理会保留背景音乐,但去除主要的人声部分。
-
-
隔离音轨:
-
通过深度学习技术,AI能够将原始音轨分解成多个音频层,例如:人声层、乐器层、鼓点层等。
-
用户可以根据需要选择不同的音轨或对特定音轨进行修改。
-
捐赠和免费支持
一些音频处理平台可能会通过捐赠的方式来支持其运营,尤其是那些提供免费工具的服务。通常,平台会提供免费的基础功能,同时鼓励用户捐赠或提供付费订阅,来维持其技术更新和维护。这样即使是免费的工具,也能通过捐赠来获得运营资金。
相关应用
-
音乐创作:为音乐创作者提供去除人声的工具,使他们能够使用现有的音轨做混音和重制。
-
卡拉OK制作:去除原唱中的人声,制作伴奏曲或卡拉OK版本。
-
音频分析:通过提取特定音轨,进行更精确的音乐分析,例如识别乐器或节奏。
-
语音隔离:对语音信号进行处理,去除背景噪音或提取特定的语音部分。
技术亮点
-
强大的AI算法:深度学习技术可以处理复杂的音频信号,做到高精度的分离。
-
实时处理:许多工具能在几秒钟内完成音频的分离处理。
-
高质量输出:通过AI模型优化,分离后的音频质量通常很高,保留了音乐的完整性。
https://vocalremover.org/zh/